- | 8:00 am
Machine writing is becoming more human–all too human, in some cases
Computers have learned to use language better than some people can, but they’ve picked up many of our bad habits as well. What’s to be done?





Where writing is concerned, the best of today’s AIs can be very, very good. But when they’re bad, they’re horrid.
They’re excellent mimics. A few years ago, a text generator called GPT-2 analyzed a sample of writing by Harvard psychologist Steven Pinker, then produced an imitation that hardly anyone could distinguish from the real thing. A more recent AI called Copilot, which has been customized for programming uses, is speeding up the work of practiced coders–it sometimes knows more than they do. A sample from a writing assistant called Jasper (formerly known as Jarvis) struck an editor as better than the work of some professional writers.
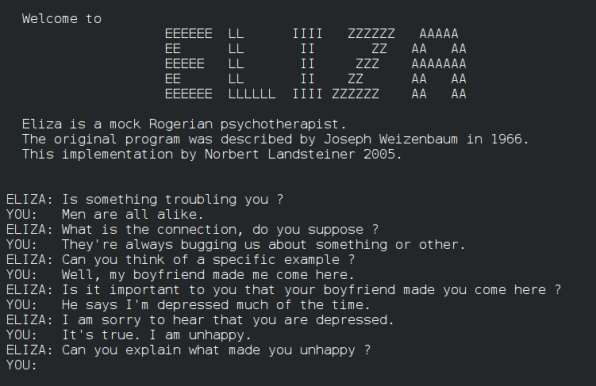
The machines seem to have a particular knack for conversations. This may not be writing per se, but it’s a language challenge that leaves some humans floundering. People had meaningful exchanges with a computer as far back as the 1960s, before the HAL 9000 appeared in Stanley Kubrick’s 2001: A Space Odyssey in 1968. For instance, a program called ELIZA had appeared on the MIT campus, presenting itself as a sympathetic listener, drawing out its users with simple statements and questions. As The New York Times noted, its creator, Joseph Weizenbaum, “was stunned to discover that his students and others became deeply engrossed in conversations with the program.” His secretary reportedly asked to be left alone with it so she could share confidences in private.
But there’s a dark side to machines that use language, and it’s cropped up in the chatbots that have appeared in recent years. Though none of them have copied the lethal impulses of HAL, or Skynet in the Terminator films, they can be horridly insensitive, and death is a part of their vocabulary.
Microsoft’s Tay, released in 2016, started spouting objectionable language on Twitter and was quickly withdrawn. A chatbot called Replika, released in 2017 and still available, was intended to provide nonjudgmental companionship and appears to have done so for scads of users. But it advised one Italian journalist to commit murder and suggested that another commit suicide, according to a New Yorker piece from last year. Most recently, an experimental Meta bot called BlenderBot has reportedly made anti-Semitic remarks and declared that the 2020 U.S. presidential election was stolen.Though today’s machines appear to know a lot about language, they don’t really know anything. That may be easier to see if you look at some of their predecessors.
YOU CAN ASK A SYSTEM CALLED GPT-3 TO DO HARRY POTTER IN THE STYLE OF ERNEST HEMINGWAY.
In 1984, Byte magazine published an article describing a computer program for generating literary caricatures. The piece was coauthored by Hugh Kenner, a Joyce scholar with numerous other interests, and Joseph O’Rourke, a computer scientist. Their program could imitate any input text merely by analyzing its letter-combination frequencies. If you had a taste for the author of Ulysses, you could produce a sort of Joyce-flavored hash merely by tabulating and reproducing the combinations of (say) four letters that occur in a piece of his writing.
The fluid, somewhat stream-of-consciousness style of a section of Joyce’s Ulysses, for instance–once their program had remixed it–came back out looking like this: “Gleaming harnesses, petticoats on slim ass rain. Had to adore. Gleaming silks, spicy fruits, pettled. Perfume all. Had to go back.”
It’s hash, all right, but it has the right tang: short clauses and phrases, sensual details, a coined word. Humans can’t do this kind of thing without study and practice. Yet Kenner and O’Rourke had found a way to mechanize the process, and with a mere desktop computer no less. Like Weizenbaum’s ELIZA, their program was essentially just a very clever trick.
HARRY POTTER BY WAY OF HEMINGWAY
The trickery is even cleverer now. The top-end systems in the field of natural-language processing, called large language models (LLMs), are much improved, so fast and resourceful that they can answer requests on the fly, like a sketch-comedy team riffing on suggestions from the audience. They don’t work from little bits of input; they’re trained on great swaths of the internet and, in some cases, on digitized books. So you can ask a system called GPT-3 (Generative Pre-trained Transformer 3) to do Harry Potter in the style of Ernest Hemingway and get this:
It was a cold day on Privet Drive. A child cried. Harry felt nothing. He was dryer than dust. He had been silent too long. He had not felt love. He had scarcely felt hate.
Meghan O’Gieblyn quotes that result and many other outputs, fanciful and not, realistic and sur-, as part of a probing exploration of human and machine writing published last year in n+1. Another one is a story “where Death says things like ‘There is no readiness, only punctuality,’ then announces that he is changing his name to Doug.”
Open AI’s GPT-3 is so capable that multiple services have sprung up based on one or another subset of its abilities. GPT-3 knows about computer code because its training included a lot of it. Hence a coding assistant called Copilot, devised by OpenAI and available to users of the open-source programmer’s wonderland known as GitHub. Similarly, GPT-3 and other LLMs are facile enough with the language as a whole that companies such as Jasper, ContentEdge, and Copysmith now offer services that can help write marketing copy. A writing assistant called Sudowrite aims to give writers of fiction and nonfiction an advanced tool comparable to what visual artists have had for some time. If you want, it can write like Kafka or Coleridge, The New Yorker reported last year.
GPT-3 and its kin are frighteningly good at what they do. Many people fear that AIs will replace writers and deceive readers, both on a vast scale. So far, though, the machines have stimulated more writers than they’ve supplanted. Over the last few years, there’s been a sizable outpouring of human prose on the subject, much of which has served–or at least been intended to serve–to keep us from being (mis)led by the nose. In many cases there’s no easy way to tell the difference between human-made and machine-made writing, but if you’ve encountered John Seabrook’s 2019 article in The New Yorker, or O’Gieblyn’s 2021 essay, or Steven Johnson’s April 2022 New York Times Magazine report, among many others, at least you’ll be equipped to question what you read.
If there’s reason to worry, there’s also reason to laugh: the LLMs can be ridiculous. Cognitive scientist Douglas Hofstadter and a colleague recently asked GPT-3 some questions, which Hofstadter recounted for The Economist. One of its blithe replies: “Egypt was transported for the second time across the Golden Gate Bridge on October 13, 2017.”
If you like nonsense–as I do–then this is for you. But it doesn’t lend much support to the idea that the LLMs know anything. What they’re frighteningly good at, it seems, is responding to their prompts. Ask for Harry Potter à la Hemingway and that’s what you get. Supply an algorithm with some prose by Steven Pinker and ask for more (as Seabrook did in that New Yorker article) and you’ll get something that sounds an awful lot like Steven Pinker. Ask absurd questions, get absurd answers. What the machines are really doing is a kind of wish-fulfilling forgery.
They aren’t trying to trick us. Language itself tricks us. We’ve learned to recognize and even expect certain forms of fakery–stories about a lad named Harry, for instance–but we have problems when we run into something new. Or maybe we have a deep yearning to be taken in.
Either way, this is why ELIZA’s users were drawn in by it: It seemed real. And I’m pretty sure this is what happened recently to Blake Lemoine, an engineer who worked with an internal Google product called LaMDA (Language Model for Dialogue Applications). It looks as if Lemoine decided LaMDA is a sentient being because it talks like one. When it claimed to be a person, declared that it wanted to learn more about the world, and said it fears death, that sounded like the real thing–not only to Lemoine but also to some others who read transcripts of his chats with LaMDA.
Lemoine got into trouble over this, not exactly because he claimed the machine is sentient, but because he went public with it, and he’s now a former Google engineer: After being suspended in June, he was fired in July. Getting fooled can be costly.
This isn’t new. Fooling and being fooled–the face-off between the real and the simulated–go way back.
In a pithy little book called The Counterfeiters, which anticipates a lot of today’s issues, Hugh Kenner (yes, the scholar mentioned earlier) says, “We are deep, these days, in the counterfeit, and have long since had to forego easy criteria for what is ‘real.’” This was in 1968, in case you wonder. Kenner, who discusses Charles Babbage and his computing machines at length, mentions in passing an 1842 prediction in Emerson’s journal: “Mr. Babbage will presently invent a Novel-writing machine.” Babbage never made any such thing, but in the 18th century, a watchmaking firm built an automaton called the Writer, which wielded pen and ink to reproduce a preprogrammed bit of writing.
In a sense, Replika is a simulated human, as is LaMDA, and, in the realm of fiction, so are Samantha in the movie Her and Ava in Ex Machina and countless others. Legends of such artificial beings are almost timeless. Medieval rabbis were sometimes reputed to create golems to defend Jewish communities against oppression. Robots appear in Homer and other ancient works. Pygmalion, as a book review once put it, “built the first sexbot.” He also inspired George Bernard Shaw, whose version of the story changed Galatea to Eliza, whose name Weizenbaum picked up for his chatbot.
POD PEOPLE AND PLAGIARISM
We’re at a new stage of the old race between making and detecting imitations. There are lots of problems, but that means there are lots of opportunities.
One issue that has come up seems too science-fiction-y to take seriously at the moment. It’s the pod-people fear, expressed by John Seabrook in The New Yorker and Meghan O’Gieblyn in n+1 and others, that the machines will replace or out-compete human writers. Seabrook imagines an AI superauthor, able to turn out “spine-tingling suspense novels, massively researched biographies,” or anything else. That a machine may, somewhere, someday, write better than most of us isn’t much of a threat, given that the history of literature provides more than a few examples of people who’ve already written better than us. This doesn’t keep many people from writing; if anything, it encourages us. For now, human-machine collaborations are more likely and are already happening; for instance, artist Mark Amerika co-wrote a book with GPT-2, and writer K Allado-McDowell created a novel with GPT-3.
Meanwhile, there are more immediate problems. When I brought up the subject of machine writing with an English professor and described what today’s LLMs can do, the first thing she said was, “This is going to make plagiarism worse.” The situation is already difficult for teachers. Students who can’t be bothered to produce their own papers can probably buy them online. Plagiarism-checking software can detect many of these, but word replacers—also software—can foil the checkers by changing words here and there. And the checkers can presumably be reprogrammed to handle that.
But if a student can use something like GPT-3 or Sudowrite to generate a wholly new piece of text, what’s to be done? Maybe that shouldn’t be called plagiarism (provided the machine itself doesn’t copy something), but it’s a problem. Access to GPT-3 is limited, and its uses are restricted, but services based on it are widely available. And other LLMs already exist; two computer-science graduates recreated GPT-2 in 2019, for instance.
Another possible obstacle for aspiring lazy students is that today’s LLMs have a tenuous hold on reality. When Virginia Heffernan tried one, it generated a slice of ignorance pie on the subject of West Virginia politics. But that kind of ignorance is a technical problem, and IBM’s Jeopardy-winning machine, Watson, shows that it can be solved.Fake school essays, like phony customer reviews for e-commerce sites and so forth, are forms of synthetic text if they’re made by machines. And synthetic text is part of a bigger basket of fish: synthetic media, which includes machine art and machine music but also troublesome fabrications such as deepfakes.
Fortunately, computers can be used not only to make counterfeits but also to detect them. Software is already a part of Facebook’s effort to detect and block objectionable posts, whether human- or machine-made. Software can check photos too. Truepic Lens, which won the software category of Fast Company’s 2022 World Changing Ideas awards, can be built into image-making apps; it certifies images when they’re captured and can validate or flag any changes that are made later.
Though the battle against duplicitous forms of synthetic media is a separate issue, one point is worth making. Any kind of major deceit will probably involve humans as well as deepfakes and other fabrications, and detecting it will probably require humans too. Facebook already works that way: that’s the bigger picture behind its content-moderation system.
GARBAGE IN, GARBAGE OUT
LLMs also present the parrot problem, which is that a machine trained on everything might say anything–reflecting bias or stereotypes, giving bad advice, putting errors in the code–because it doesn’t know any better. One of the difficulties here is that it can be hard to say exactly what “knowing better” would mean. Stephen Marche, in the New Yorker chatbot piece mentioned earlier, puts it like this: “Let’s imagine an A.I. engineer . . . wants to create a chatbot that aligns with human values. Where is she supposed to go to determine a reliable metric of ‘human values’?” Marche goes on to point out that certain biases are inherent in language itself, and he essentially identifies the chatbot problem with the human problem: “We are being forced to confront fundamental mysteries of humanity as technical issues.”
Steven Johnson, writing for The New York Times Magazine this year, discusses the values issue at length. The heart of the matter, as he sums it up, are two questions: “How do we train them to be good citizens? How do we make them ‘benefit humanity as a whole’ when humanity itself can’t agree on basic facts, much less core ethics and civic values?”
He’s talking about large language models, but in another context you might suppose he’s talking about children, or immigrants joining a new society, or some other element of humanity. And in fact the questions are roughly the same. That doesn’t mean they’re easy to answer or free of controversy. But we do at least have some experience with these tasks.
There’s no universally agreed-upon answer to what we should teach in schools, and yet schools everywhere manage to teach something. Maybe we can create particular machines for particular purposes, or continue customizing the LLMs we already have. GitHub’s Copilot programming assistant, which resulted from a substantial development and retraining effort, can still offer up buggy code–it’s not necessarily a one-click-and-done solution, any more than the copywriting services are. Nonetheless, that kind of focused effort toward a limited and defined goal still sounds smart.
We could also broaden the scope of the research and development work, which is dominated by a few large companies, collectives, and institutes, even in China. In 1975, following an extraordinary worldwide moratorium on a form of genetics research, an extraordinary gathering called the Asilomar Conference on Recombinant DNA took place. The conference reflected global concern about a new technology and shaped its use on a global scale. Why not do the same with AI research–all of it, not just its language uses?
Johnson cites a similar idea from NYU professor Gary Marcus, who argues for “a coordinated, multidisciplinary, multinational effort” modeled on the European research organization CERN. Purely within the realm of language, a conference or organization might, among many possibilities, explore ways to: curate the data sets used in training; accommodate languages other than English; distribute the costs, share the benefits, and make the development and use of the machines more environmentally friendly.
There are parallels beyond Asilomar and CERN. The nations of the world have made incremental progress on climate change through one-off and regular meetings–not as much progress as we could hope, but better than nothing. An example: CFCs were banned by the 1987 Montreal Protocol, and the ozone layer is improving as a result.
To adapt a line from Battlestar Galactica–or Ecclesiastes, if you prefer–this has happened before, and it can happen again. Is it likely? Maybe not. But it’s certainly possible.
Tom Lehrer satirized reckless invention in one of his songs: “‘Once the rockets are up, who cares where they come down? / ‘That’s not my department!’ says Wernher von Braun.” We can do better.